终于可以稍微松口气了,继续更 Dandelion 系列 ![]()
转载自我的博客,原文链接:图形学实验框架 Dandelion 始末(三):OpenGL API 抽象与实时渲染
OpenGL 标准描述了一种 C/S 架构的 GPU 编程模式:CPU 上执行的程序是 Client,通过调用 API 可以查询或更改全局状态,也可以请求渲染;GPU 是 Server,响应查、改状态或渲染的请求。这种设计思路导致编程时需要时刻考虑许多状态,而每次进行渲染都要更改若干个状态。为了更方便地管理这些状态,我在 Dandelion 框架实现中对 OpenGL 略作封装,屏蔽了大部分细粒度的状态修改操作。
实时渲染需求与顶层 API
我在第一篇文章中提到过:Dandelion 中存在两种渲染过程,分别是用于预览的实时硬件渲染与用作实验的离线软件渲染。本文只讨论其中硬件渲染的部分,软件渲染与 OpenGL 无关。
由于 Dandelion 是参照 Blender 设计的,对实时预览的着色效果要求很低,只需分辨出物体的形状即可。除了场景中的物体以外,
- 在渲染模式下还需要渲染出相机的视椎体以便调整渲染相机、渲染出设置好的光源
- 在建模模式下还需要渲染出 mesh 的顶点和边来强调基本图元
这些渲染需求可以概括为渲染顶点、线条和面片三类图元,而每一类图元的渲染效果是相同的,不同情况下渲染任务的差别在于待渲染图元的差别。因此,我准备用两个顶层的渲染类来满足两大类渲染需求:
GL::Mesh面向以 mesh 为数据源的渲染任务GL::LineSet面向以线条为数据源的渲染任务
最初我以为二者既然功能不同,实现起来应该也有明显的差异。但很快就发现 Mesh 有时也需要渲染线框,导致两个类的渲染函数 Mesh::render 与 LineSet::render 实现起来几乎没有区别,或者说 LineSet::render 完全是 Mesh::render 的一部分,只不过去掉了选择被渲染图元类型的代码。所以这里只聊 GL::Mesh 的渲染过程。
根据我对 GL 这个 namespace 的功能规划,GL::Mesh 只负责处理渲染操作,而不关心这些渲染操作的语义是什么。比如调用 Mesh::render 时指定渲染边和顶点,而不是指定渲染 Mesh 的“线框”;或者指定渲染面片,而不是 Mesh 的“实体”。因此,Mesh::render 需要完成的工作就是根据图元类型绑定 VAO、设置颜色和材质并发送 draw call,而 GL::Mesh 类中需要维护的信息就是与这个 Mesh 有关的 VAO 和数据 Buffer。
Dandelion 实时渲染的基本流程和上一篇文章中渲染地面网格的过程基本一致:
- 在
Controller::render函数中,根据main_camera的参数计算出 View / Projection 矩阵,并设置 shader 中的 uniform 变量。 - 进入
Scene::render函数,遍历所有的Object并调用Object::render函数渲染物体。 - 进入
Object::render函数,设置 shader uniform 变量传入 Model 矩阵和材质参数,遍历所有的GL::Mesh对象,调用GL::Mesh::render渲染 mesh。 - 调用
glDrawArrays/glDrawElements绘制图元。
在这个流程中,Scene 和 Object 是具有语义的“场景”和“物体”,而 Mesh 则是位于下层的“无语义对象”。这里的无语义,是指它在 UI 上不存在对应物,也不直接与用户产生任何交互,用户不会感受到它的存在。当程序加载模型文件后,场景不再为空,每一帧渲染时 Scene::render 函数就会调用每个物体的 Object::render 函数,而在 Object::render 中会调用 Mesh::render 函数完成渲染。对于绝大多数情况来说,Mesh::render 就是最顶层的渲染 API,将场景、物体这样具有语义的对象与只负责完成渲染的抽象层分隔开。
之所以说“绝大多数情况下”,是因为诸如光源(绘制为六个点)、地面(绘制为若干网格线)等特殊对象都不是由
Mesh或LineSet渲染的,而是调用了更低层级的 API。这些例外的原因是我实现的Mesh和LineSet不够灵活,不支持逐顶点指定颜色等操作,无法实现我想要的效果。加之经验尚浅、开发时间有限,最终留下了一些不甚规整的代码。
低层 API
有顶层自然有下层,上文也提到 GL::Mesh 和 GL::LineSet 都需要管理 VAO 和各类 Buffer,而 OpenGL 中管理这些对象的过程也需要设置许多状态。如果各处都直接调用 OpenGL API,那么到处重复设置状态的代码显然对可读性和后续开发都有负面影响。这个问题引出了第一类低层 API,即负责管理资源的 API。另一方面,CPU 端的 OpenGL API 是一套 C API 而不是 C++ API,它大量使用宏来表示类型,不能很好地配合类型检查;由于渲染操作自身的复杂性,一些函数接口的参数列表很长且有些容易混淆,对于 Dandelion 来说是灵活过度而可读性不足的。因此有了第二类低层 API,即负责简化 OpenGL API 调用的 API。
资源管理
Dandelion 需要管理的 OpenGL 资源有三种:
- Buffer Object:存储顶点属性或顶点索引的缓冲区,对应
ArrayBuffer和ElementArrayBuffer两个类 - Vertex Array Object:记录顶点属性格式的对象,对应
VertexArrayObject这个类 - Material:在 Shader 中使用的材质
根据 GL::Mesh 和 GL::LineSet 的设计,每个 Mesh 或 LineSet 是一个最小的渲染单位,诸如 glDrawArrays 或 glDrawElements 这样的 draw call 都是由它们产生的。因此,每个渲染单位持有一个 VAO 及若干 Buffer Object,Mesh 还有自己的材质。
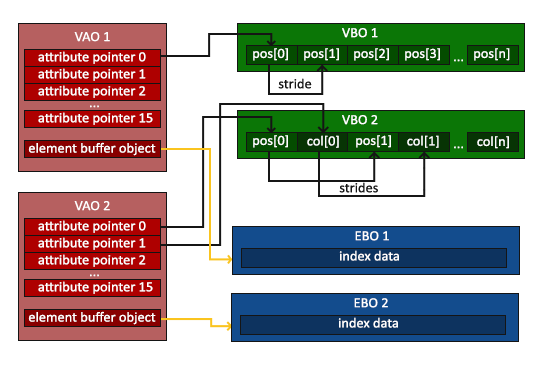
通常来说,资源管理的主要工作是管理资源对象的“生命周期”,也就是创建、转移和销毁的过程。而由于 OpenGL 以状态机的方式工作,Dandelion 还需要额外管理资源的切换过程,在渲染不同的渲染单位时正确地绑定所需的资源。
在上述的三种资源中,材质只是一组静态的数值属性,并没有独立的生命周期。我只需要正确编写 buffer object 与 VAO 的构造和析构函数,就算是完成了管理二者生命周期的代码。除了包装 glGenBuffers、glGenVertexArrays 等 API,更重要的是禁止对 buffer object 或 VAO 的拷贝构造。因为这些资源并不存在于 Client (CPU) 端,内存中的 ArrayBuffer 实例只不过持有它的编号 (name) 而已。通过拷贝构造复制一个 ArrayBuffer,只能复制其编号而不能复制真正的 buffer,这种浅拷贝在 Dandelion 中毫无意义,只会增加产生 bug 的可能性。相应地,虽然目前还没有移动 buffer object 或 VAO 的需求,但把某个 mesh 转移到另一个物体下也是合理的,所以我还是实现了它们的移动构造函数。
虽然复制一个 mesh 在逻辑上完全合理,但由于持有了不可拷贝构造的 buffer object 与 VAO 对象,所有的渲染单位也都无法拷贝构造。后续版本可能会重新实现 GL::Mesh 的拷贝构造函数以进行深拷贝(创建新的资源)。但无论是否允许拷贝构造,我始终认为应该禁止拷贝赋值以强制开发者借助引用 (reference) 来操作一个 GL::Mesh,否则很可能一次不经意间的赋值就会徒劳无功地消耗大量资源。
Buffer object 或 VAO 能够完成的切换操作包括绑定(解绑)自身和操纵顶点属性两种。由于一个 buffer 的数据格式与用途通常不会改变,我倾向于尽量将 buffer object 的各种信息在构造时固定下来。Dandelion 中的 buffer 都是为了提供顶点属性或索引存在的,因此属性或索引的格式可以认为是 buffer 类型的一部分,体现到类定义上就是模板类 GL::ArrayBuffer<T, size>。它通过模板参数 T 指定数据类型、size 指定每个顶点对应多少个数据元素。表示 buffer 使用方式的 hint 信息与对应顶点属性的位置则作为类内属性在构造时指定。这样一来,在调用 glVertexAttribPointer 将该 buffer 指定为相应顶点属性的数据源时,所需的参数都已经包含在类内了,于是我便可以将这个调用也封装起来,变成一个无参的函数 GL::ArrayBuffer::specify_vertex_attribute。
在上述封装的基础上,绘制过程就不再需要人工记忆并传递大量参数,大致变成了这样:
- 调用 VAO 的
bind()来记录绑定信息和顶点属性数据源 - 调用数据源 buffer 的
bind()和to_gpu()方法传输数据,再调用specify_vertex_attribute()方法指定它成为顶点属性的数据源 - 调用 VAO 的
release()解绑,至此数据已经准备完毕 - 在需要发起 draw call 处,绑定 VAO 并直接调用
glDrawArrays或glDrawElements即可
上述第 1 到第 3 步发生在 GL::Mesh 的构造过程中,而第 4 步正是在 GL::Mesh::render 里执行的。
简化调用
负责管理资源的封装代码其实已经起到了简化 API 调用过程的作用,不过还有一些封装是与资源无关的,它们只是一些工具代码。
类型转换
OpenGL API 在格式上是一套 C API,这意味着它不支持函数重载、不支持模板函数。因此 glVertexAttribPointer 之类的 API 不得不用参数来指定传输的数据是什么类型,而指定类型的参数也只能是一些宏定义,这样的代码很难直接与 C++ 的泛型系统配合起来。好在现代 C++ 提供了比较完善的编译期计算功能,可以很方便地将类型转换为宏。我在代码中实现了一个专门转换类型的函数 get_GL_type_enum:
template<typename DataType>
constexpr GLenum get_GL_type_enum()
{
if constexpr (std::is_same_v<DataType, char>) {
return GL_BYTE;
} else if constexpr (std::is_same_v<DataType, unsigned char>) {
return GL_UNSIGNED_BYTE;
} else if constexpr (std::is_same_v<DataType, int>) {
return GL_INT;
} else if constexpr (std::is_same_v<DataType, unsigned int>) {
return GL_UNSIGNED_INT;
} else if constexpr (std::is_same_v<DataType, float>) {
return GL_FLOAT;
} else if constexpr (std::is_same_v<DataType, double>) {
return GL_DOUBLE;
} else {
return GL_NONE;
}
}
结合 if constexpr 语法和 is_same_v 模板可以在编译期根据类型返回相应的宏值,于是我就能在 GL::ArrayBuffer::specify_vertex_attribute 中这样传递类型:
template<typename T, std::size_t size>
void ArrayBuffer<T, size>::specify_vertex_attribute()
{
GLenum data_type = get_GL_type_enum<T>();
glVertexAttribPointer(this->layout_location, size, data_type, GL_FALSE, size * sizeof(T),
(void*)0);
glEnableVertexAttribArray(this->layout_location);
}
修改 Buffer 数据
当用户修改了某个 mesh 的顶点等属性时,Dandelion 必须相应修改 buffer 内容再传输到显存才能反映到界面上。因此 GL::ArrayBuffer 和 GL::ElementArrayBuffer 都提供了增加、修改数据的方法。之所以不能删除数据,是因为通过 OpenGL API 传递的数据都是数组,删除的代价太大,不如重建一个。
既然 buffer 中存储的数据是受限的(类型 T 与属性大小 size),那么更新或增加数据的操作当然也应该检查传入的新数据是否符合这些限制。C++ 的 Parameter Pack 机制允许编写参数个数可变的函数,而 Fold Expressions 机制让我能够方便地检查所有参数的类型是否一致:
template<typename T, std::size_t size>
template<typename... Ts>
void ArrayBuffer<T, size>::append(Ts... values)
{
// && 这样的双目运算符可以配合 ... 解包参数实现“链式”运算:先检查前两个参数的类型是否都为 T,
// 然后将检查结果与第三个参数的类型检查结果作逻辑与,以此类推将所有检查结果都。
static_assert((std::is_same_v<decltype(values), T> && ...),
"ArrayBuffer: all values to be appended must have the same type as T");
// sizeof... 运算符可以获取 parameter pack 中的参数个数
static_assert(sizeof...(values) == size,
"ArrayBuffer: number of values to be appended must be same as size per vertex");
(this->data.push_back(values), ...);
}
不得不说虽然看起来很黑魔法,但理解之后确实方便,堪比 Python 的 all 函数了——更何况这些都是编译期计算,没有任何运行时开销。
回顾
在一学期结束后再去回顾这部分的设计,最大的败笔是在 GL::Mesh 与 GL::LineSet 中重复写了两遍极其相似的代码。同门师兄弟聊起来的时候,大家提到专用的 LineSet 也是个常见的设计,大概是专业工具中的逻辑更复杂,需要专门优化渲染线条的过程吧。不过 Dandelion 是一个小型的实验框架,既没有那么多的精力处处深入优化,也希望代码尽可能精简以便感兴趣的同学自己分析理解,所以我还是认为最好去掉这部分冗余。接下来的重构过程中,我应该会将 GL::Mesh 与 GL::LineSet 合并为 GL::RenderUnit,作为产生 draw call 的最小单位加以管理。
至于 RenderUnit 到底是否应该允许复制,这是一个操作逻辑与性能优化的综合问题。如果我实现了浅拷贝(物体可以共享下层的 buffer object 和 VAO 但不共享名称),就可以引入 OpenGL 实例化绘制的 API,极大程度地减少渲染大量相同物体时的 draw call 数量,从而让粒子系统成为可能。而如果我实现了深拷贝(创建新的 buffer object 和 VAO),就能创建可分别编辑的实例,为几何编辑(建模)过程中提供不少方便。如果更进一步,浅拷贝与深拷贝都实现后还能实现写时拷贝 (Copy On Write, COW) 机制,Scene / Object 的代码中要拷贝 RenderUnit 就不必专门考虑深浅拷贝了。这些优化工作量相当可观,我目前也还很犹豫是否要动手开始。
下回分解
讲到现在为止,我只简单提到 Dandelion 是通过切换模式来完成不同任务(渲染、建模、物理模拟)的,还没有解释切换模式时 UI 层面、场景层面、数据(资源)层面发生了怎样的变化,也没有解释另外的三个模式如何运作。我计划在下一篇文章中聊聊渲染模式以及 Dandelion 离线渲染部分的设计思路,也讲讲如何拓展 Dandelion 的渲染能力。