转载自我的博客,原文链接:https://greyishsong.ink/图形学实验框架-Dandelion-始末(四):渲染模式与软渲染流程/
GAMES 101 的实验中包含了经典的光栅化渲染、Whitted-Style Ray-Tracing 和路径追踪,加上闫老师高质量的课程内容,已经把局部光照渲染和全局光照渲染这两种视角展示得很不错了。但我从开始做 101 的实验时就产生了一个遗憾——为什么不能用我自己编写的工具来渲染任何我想要渲染的模型呢?而这正是 Dandelion 想要弥补的地方。
软件渲染的工作方式
如今硬件渲染管线已经主宰了大多数渲染应用领域,那我为什么还要选择软件渲染呢?这也是受到闫老师 GAMES 101 实验的思路的启发,即一门基础课程应该介绍渲染管线,而不是图形 API;偏重流程、光照和着色,避免过度强调性能优化。
渲染引擎与渲染器
回顾第一篇文章里我所设想的“功能性要求”:
由于我们希望这个框架能实现各种渲染流程,显然它应该像 Blender 一样可以切换“渲染器”,每个渲染器都对应一种渲染管线。为避免某个实验过于艰深,可以牺牲管线的灵活程度,只保留较少的可编程部分。
为了实现它,我将一次渲染的过程拆分为两部分:
- 与渲染算法甚至渲染管线基本无关的部分,包括读入场景、输出 frame buffer、展示到屏幕上等等
- 根据场景、光源和视角生成图像(frame buffer 内容)的部分
在 Dandelion 中,第一部分由“渲染引擎” RenderEngine 承载,第二部分由“渲染器” Renderer 实现。从界面上启动一次渲染的流程是这样的:
- 编辑好场景,设定光源和相机
- 点击 Render to Image 按钮,UI 组件调用
RenderEngine::render方法,传入场景和所选的渲染器开始渲染 RenderEngine根据传入的类型调用相应渲染器的render方法- 渲染器将渲染图写入到
RenderEngine::render_res中 - 调用
glTexImage2D将RenderEngine::render_res转换为一张纹理贴图,然后用ImGui::Image展示出来
在整个流程中,RenderEngine 的主要作用就是传参和提供 buffer,有些类似设计模式里提到的的适配器 (Adapter) ,主要作用是统一接口。在此之下,真正完成着色计算的是渲染器。
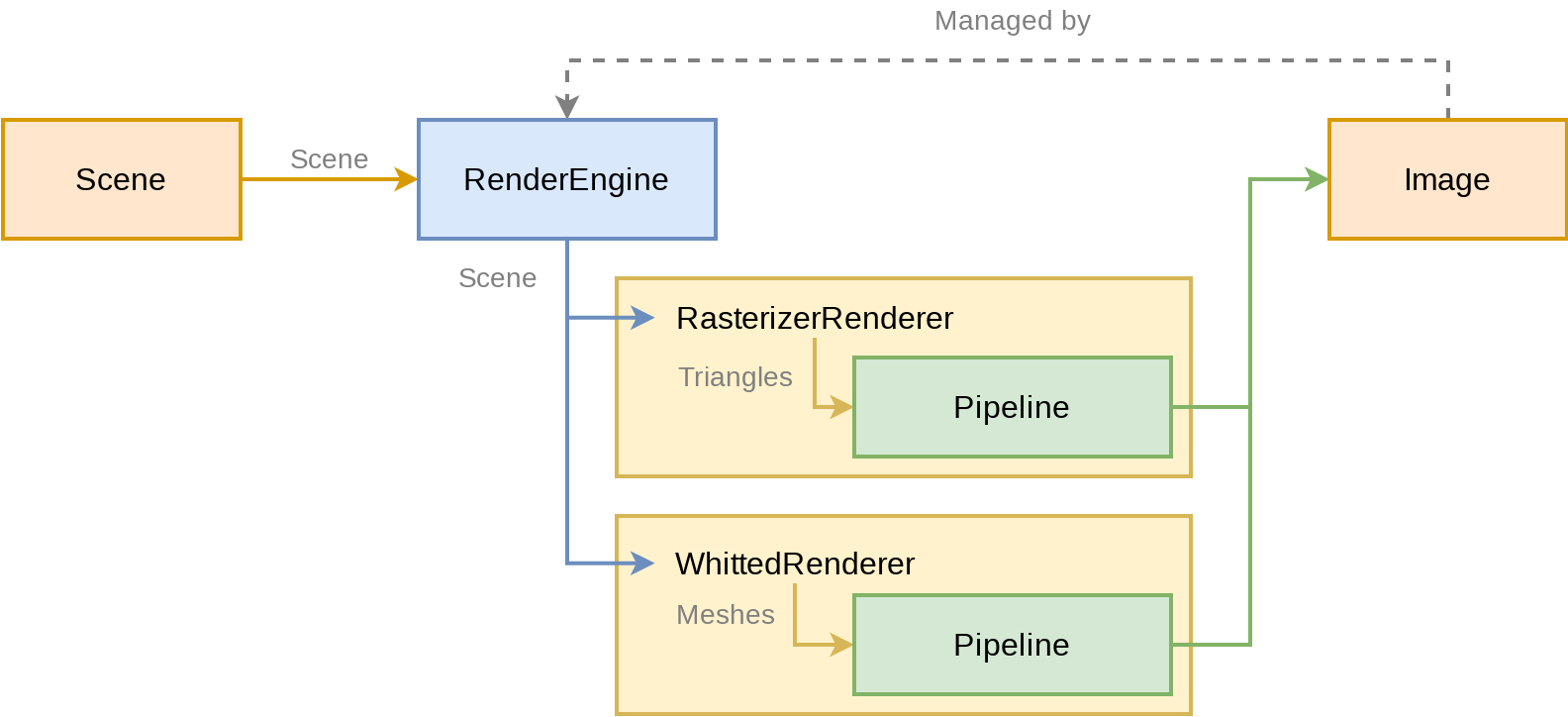
由于 Dandelion 管理场景对象的部分与渲染模块是分离的,渲染器按照约定的层次遍历场景即可获得渲染所需的数据,不必关心读取和解析文件的问题;不同渲染器之间可以共用的配置则存储于 RenderEngine 中,在调用渲染器渲染时传入。
渲染管线
虽然在界面上有三个渲染器选项,但实际上 Dandelion 只实现了两个渲染器,分别是 RasterizerRenderer 和 WhittedRenderer。这两个渲染器的主干代码分别移植自 GAMES 101 的实验 3 和实验 5,不过为了将其适配到 Dandelion 中作了不少修改。我们也修复了 GAMES 101 作业中的一些 bug,例如缺少正确的透视矫正等等。这部分工作主要由我的同门 JoTaiLang 完成,他几乎将数月的业余时间全部投入到了渲染器的移植和调试中,没有他的帮助,我恐怕绝不可能在七月初完成 1.0 版本。
RasterizerRenderer 配合另一个类 Rasterizer 实现了包含 Vertex Processing、Rasterization、Fragment Processing 和 Blending 四个阶段的极简光栅化管线,支持 z-buffer 消隐。每个 shader 是一个函数,有相应的 payload 作为输入。不过由于需要处理的变量更多,代码中增加了一个静态结构体 Uniforms,所有的 shader 都可以从中读取“全局变量”。由于这两个 shader 都是通过 std::function 指定,开发者也可以像使用 GLSL shader 那样修改其中的内容甚至在运行时切换 shader。渲染时由 RasterizerRenderer::render 将场景中的 mesh 整理成无序的 TriangleList 送入 Rasterizer::draw,依次对每个 Triangle 进行顶点处理、光栅化和片元处理。
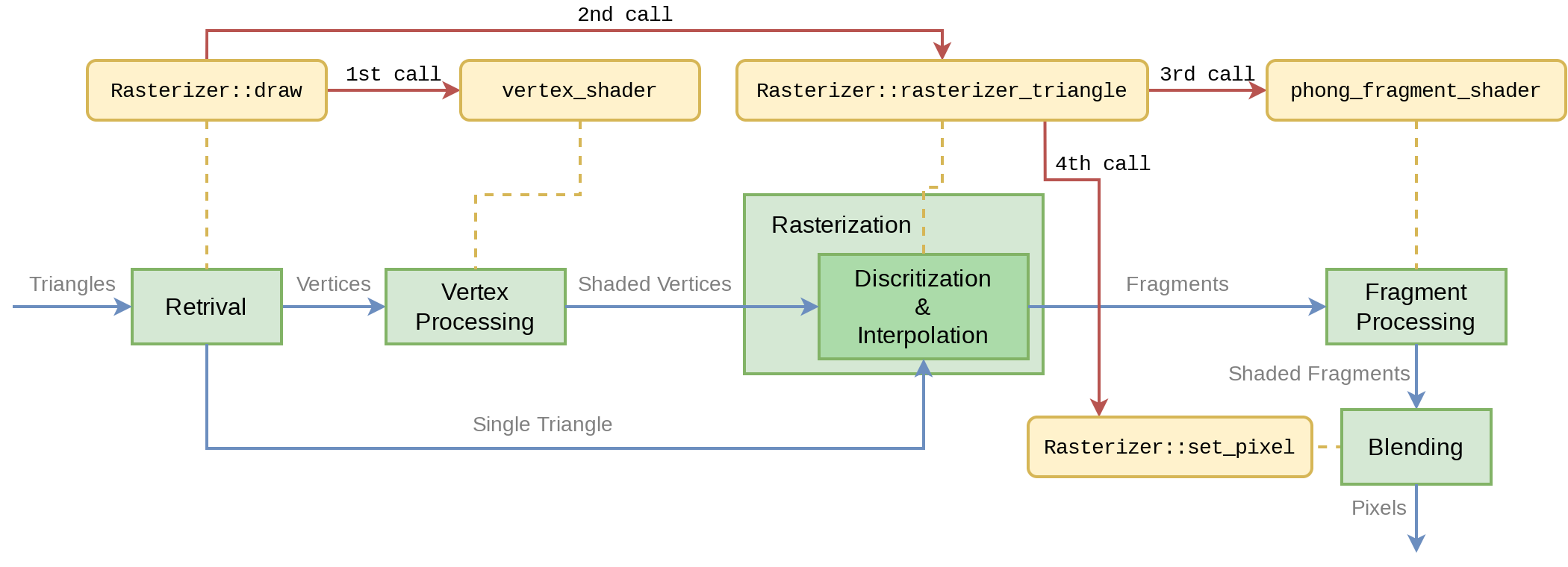
上图中蓝色箭头表示数据流动方向,红色箭头表示函数调用关系,可以看到渲染的核心逻辑都集中在 Rasterizer 内部。但为什么渲染器还要调用 Rasterizer 才能完成渲染呢?这是沿用 GAMES 101 实验框架设计的结果,尽管我不太能理解这样做的意义何在——相反,我甚至觉得这样的设计并不是很好,至少当前就体现出了两个问题:
RenderEngine是静态对象(由UI::Toolbar构造),Renderer 也是静态对象(由RenderEngine构造),只有Rasterizer在每次渲染时重新构造然后销毁。由于Rasterizer中保存了大量的参数和中间结果(例如 MVP 变换、frame buffer 副本和 depth buffer),在 frame buffer 和 depth buffer 每次都需要手动覆写(用背景色或无穷大填充)的情况下,重新构造它们既不能省去覆写的代码,也不能提高执行的效率,这样的设计就显得很多余了。从直觉角度来说,光栅化器和要渲染的场景是无关的,对应到代码中也应该是静态的(或者至少是固定的)。- 我们有一个四阶段的管线,但实际上这四个阶段都不在
RasterizerRenderer::render函数内执行,而是在Rasterizer::draw函数内执行,前者近乎是后者的简单包装。把调用 vertex shader 和 fragment shader 的代码写到Rasterizer当中,后来者再读代码时便很容易感到迷惑:这个光栅化器到底是负责光栅化还是整个渲染流程的?如果它负责执行整个流程,那光栅化渲染器又起什么作用?
当然,我们依然非常感谢 GAMES 101 实验的设计者们给出了功能大致正确并且风格比较规整的代码框架。在初步完成 Dandelion 的过程中,有限的水平和比较紧张的时间一度让我们相当焦虑,因而没有大改光栅化渲染器的结构,基本上就是将原先的顶层入口替换成了 RasterizerRenderer,再将原先的 Rasterizer 类移植进来并适配 Dandelion 的场景格式。这部分代码在 2.0 版本中多半需要略作重构,至少要避开每次重新构造 Rasterizer 的尴尬。
话说回来,我们感到时间紧张一方面是因为水平有限,另一方面是因为较大幅度地修改了光线追踪的代码。相较于所有代码都在 渲染 子模块下的光栅化渲染器,Whitted-Style 光线追踪渲染器的实现则分散在 渲染 render 与 工具 utils 两个子模块中。我们首先从 GAMES 101 实验中拆解出负责着色的代码,然后将其移植到渲染子模块;再拆解出射线求交和 BVH 加速的代码,半移植半重写地加入工具子模块。
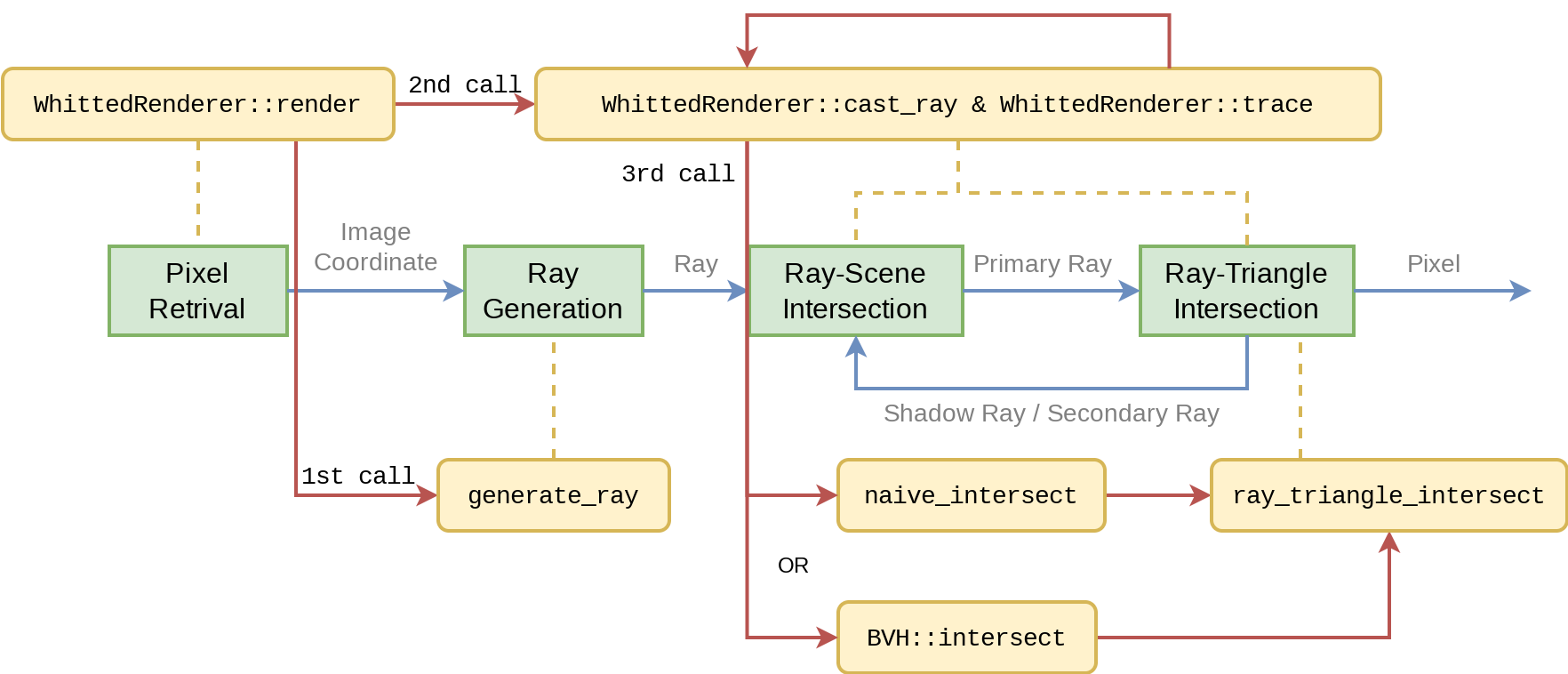
图中代表函数的黄色框分成上下两半,上半部分是 WhittedRenderer 自身的方法,下半部分则是 utils 中的工具函数。
这一设计思路来自于我对 CMU 15/462 实验框架 Scotty3D 的使用经验:它也是个全功能交互式框架,但在渲染方面只考虑了路径追踪 (Path Tracing) 技术,将射线生成、射线求交、BVH 加速等代码全部置于 PT 这个命名空间下,相当于将这些功能统一划归路径追踪渲染器。然而,拾取操作(在屏幕上点击物体就可以选中它,通常被叫做 picking)通过从视点发射一条射线来将屏幕坐标系中的点击操作转换为世界坐标系中的选择过程,因此它同样依赖于射线求交过程。于是 Scotty3D 的 UI 代码中必须调用路径追踪子模块的代码,甚至是一些与渲染功能耦合比较紧密的代码,在我看来逻辑上略显混乱。拆解之后,Dandelion 的 UI 子模块和渲染子模块共同依赖射线相关的工具代码(utils/ray.h 与 utils/bvh.h)。
最终,光线追踪渲染器的结构变得很简单:以 WhittedRenderer::render 作为渲染入口,在深度为 1 的假想渲染平面上划分像素网格并调用 utils/ray.h 提供的 generate_ray 根据图像坐标生成射线,对每条射线调用 cast_ray 求交并完成着色计算,即可得到图像。
实现 Whitted-Style 光线追踪时,我们为了直接沿用
GL::Material的材质格式,小小地取了一点巧:在 Phong 模型材质的基础上,约定将 shininess > 10^3 的材质都视为镜面,即着色时只反射环境颜色而没有自身颜色。
拓展 Dandelion 的渲染能力
性能优化
由于每个像素都进行相同的计算(着色),渲染是一个非常适合并行优化的过程。例如 Blender 的 Cycles 渲染器在使用 CPU 渲染时可以达到 99% 以上的 CPU 占用率,这意味着实现合理的并行渲染程序可以完全发挥 CPU 算力。
在移植完 RasterizerRenderer 之后,我们又实现了一个多线程版本的光栅化渲染管线。不过多线程和单线程的渲染逻辑基本一致,所以另外定义一个多线程光栅化渲染器类并不必要,我们也就只增加了若干带有 _mt 后缀的函数以便共用配置和初始化的代码。在不涉及外部交互的情况下,直接使用 std::thread 写出一个多线程版本并不困难。真正决定性能的重点在于:规划哪些数据要被复制给每个线程,成为线程局部数据 (thread local data);哪些数据还是保留在主线程内,成为共享数据。
JoTaiLang 同学一开始就确定了要将所有的三角形(面片)分配不同的线程,因为使用局部光照模型时不同的面片之间毫无影响,面片不仅可以直接被分配给不同的线程,而且在 join 时也不必合并。然而 frame buffer 和 depth buffer 就不是那么好处理了,不同的线程可能会写同一个像素处的颜色(或深度)值,这种写冲突是不可避免的。此时我的想法是索性准备 N_\text{threads} 个 buffer,每个线程首先写自己的 buffer,到 join 时再将所有的 buffer 根据深度值合并起来。于是 JoTaiLang 分别测试了两种方案的性能:
- 全局加锁:当某个线程要写 frame buffer 时,将 depth buffer 和 frame buffer 都锁上,写完一个像素后再释放锁
- 多个 buffer:每个线程单独创建 frame buffer 和 depth buffer,join 后在主线程根据每个 depth buffer 的值决定来合并 frame buffer
测试的结果并不如我所愿——虽然多个 buffer 的方案完全消除了锁操作,但用时反而比全局加锁的方案更长一些。所以我们最终选择了全局加锁的方案,也没有继续尝试细粒度锁或加速 buffer 合并的方案。不过在仅使用全局锁的情况下,启动 8 个线程便能够达到 4 以上的加速比,可见光栅化三角形与片元着色(无共享数据部分)的开销应当明显大于写 buffer(有冲突的部分)的开销。
完全无优化的光线追踪会调用 naive_intersect 函数计算光线与 mesh 的交点,这个函数会遍历 mesh 中所有的面片并调用 ray_triangle_intersect 进行求交,实现很简单但效率非常底下。我们移植 GAMES 101 实验中的 BVH 代码后,光线追踪效率有了质的飞跃,甚至可以在几十秒内渲染 Stanford Dragon 2 模型(约 36 万面片)!于是我们就转移精力去写其他部分的代码了,没有为光线追踪实现多线程优化。
说来我们在移植 BVH 代码时还有个小插曲:GAMES 101 的实验代码完全没有考虑物体的 model 变换(或者说默认 model matrix 是个单位矩阵),因而直接将 BVH 建立在了世界坐标系下。然而 Dandelion 允许用户对物体进行多种线性变换,如果还将 BVH 建立在世界坐标系下,每次变换物体都要更新整个 BVH,这是不可接受的。因此我们加入了两个修改:
- 将 BVH 由场景级降为物体级,每个物体都有一个自己的 BVH(以
Object::bvh类属性的形式存在) - BVH 建立在模型坐标系下,物体被线性变换后无需更新 BVH
不过,这也导致射线(光线)与物体求交之前必须被变换到物体的模型坐标系下,好在这样的代价不大,完全可以接受。
更多效果
目前的光栅化渲染管线尚不支持生成阴影,不过完成渲染后 RasterizerRenderer 中的 depth buffer (z-buffer) 会被更新为当前视角下的深度图,所以只要对 RasterizerRenderer::render 函数稍作扩展就可以在其中实现 2-pass rendering,并利用深度图实现 shadow mapping。类似的 multi-pass rendering 理论上也都不需要大改代码。
对于光线追踪渲染管线来说,只需在材质(以及材质编辑 UI 组件)中加入透明度和折射率属性,再少量修改 WhittedRenderer::cast_ray 的代码,即可支持渲染透明物体。
以上都是些零打碎敲的修改,如果我们能实现一个多模式的材质系统(至少添加 PBR 材质模式),物体将不再局限于 Phong 光照模型;再进一步,我们就可以将结合了 PBR 的路径追踪渲染管线实现为一个新的渲染器 PathTracingRenderer,让 Dandelion 能够渲染出更加惊艳的图像。这无疑是 2.0 版本最具挑战性的目标之一,希望我们能够在明年达成。
下回分解
渲染模式的大部分工作并非由我完成,因此我对这部分的发言权也有限。而建模模式是我一手设计、实现并调试的。虽然我从 Scotty3D 中移植了不少代码,但也自己实现了一些行之有效的优化。2022 至 2023 学年秋季学期上课时,许多同学的轻薄笔记本在进入 Scotty3D 的建模模式时帧率大跌,甚至卡顿到完全无法操作 (< 5 FPS) 。而 Dandelion 运行在一台主流轻薄本上时,支持建模模式操纵数十万面片的 mesh 并维持 30+ FPS 的帧率,并且还没有牺牲多少易用性和视觉效果!虽说这些优化更近乎是 trick,但它们的实际效果实在是让我很有成就感。
下一篇文章我会回忆一下在 Dandelion 中加入建模模式与半边网格 (Halfedge Mesh) 数据结构的过程。除了算法和调试的问题外,建模模式在 GUI、状态、交互方面带来的复杂性相当大,可以说超过了其他模式的总和,也让我在最初构建 GUI 时犯下的错误彻底爆发。希望这些经验能够帮助后来的同学们,也希望这段记忆能在我的脑海中留得更久一点。